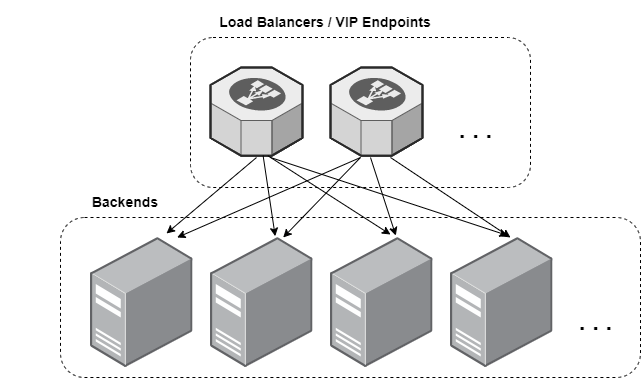
Previously I gave some background on TCP over anycast, discussing the motivations and some possible challenges, now I'd like to talk about implementations. As a quick reminder, the situation we have looks like the diagram below and we are looking to gain redundancy/availability in the load balancing layer such that traffic for a single connection can arrive at any endpoint/load-balancer and still be forwarded to the backend that initially handled the connection.
Single-node Failover
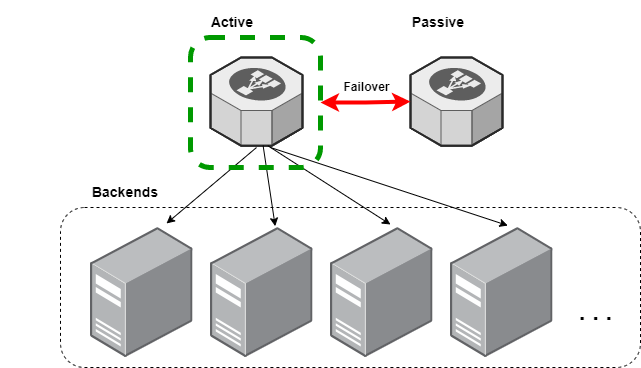
This is probably the most common approach taken and may seem like the simplest. We discussed before how allowing multiple endpoints advertising an address leads to issues if traffic for a single connection arrives at different endpoints. It seems like a really easy way to address this is to only ever advertise from a single endpoint and failover to a passive standby server as needed. There are some additional things that we should consider when choosing this option though.
One very obvious drawback is that we are always sitting on substantial (50%!) idle capacity with our failover nodes. Another is that we are only able to scale up and not scale out; this may or may not be a problem depending on your requirements. Somewhat related is that we will need to figure out how to distribute the services we are exposing across our pairs of load balancers.
Finally, if you've ever worked with distributed systems you know that reliably and accurately detecting failures is non-trivial, and thus so is automatically failing over. A well-known VIP failover mechanism is VRRP and there are many similar proprietary options available. All of them rely on the clustered load-balancers to be specially-configured on a single LAN and – at least to me – seem somewhat complex. From where I sit, if I can avoid the complexities of a setup that relies on failover I would prefer to do so.
HA with fully-shared connection state
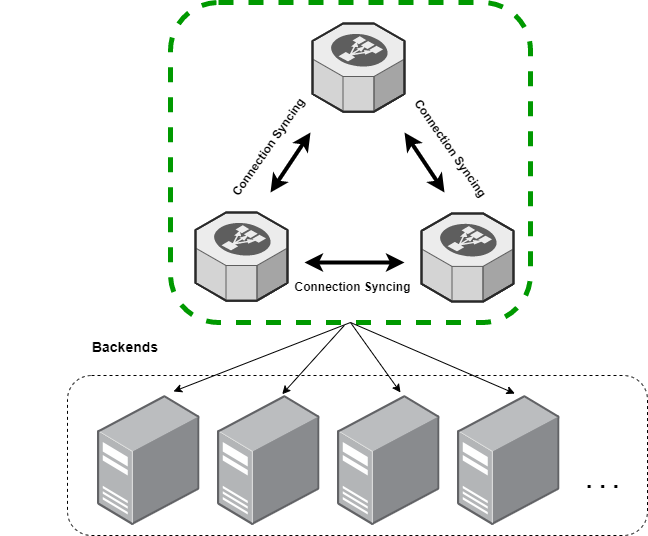
This high-availability setup mitigates many of the drawbacks of the single-node implementation. The basic idea here is that all the load balancers are sharing a single global table of connections. When a load-balancer selects a backend for a connection, it tells all the other load-balancers the connection details and the backend that was selected so they can store the information. Losing a load-balancer here is no big deal because all are equally capable of handling traffic from any of the connections they are collectively sharing.
This kind of setup introduces some operational complexity though because now nodes in a cluster either need to know about each other or be on the same LAN (utilizing broadcast for sharing and discovery). The latter is popular among open source solutions. This is not necessarily an impossible barrier to overcome, but it likely will make your setup more static.
There's also additional resource overhead as a result of state sharing. For a load-balancer cluster handling 100k connections per second the compute and network overhead of sharing connection state is non-negligible. If we very conservatively assume 8 (address information) + 4 (port information) + 8 (IP packet carrying the information from one host to another) bytes per TCP connection will need to be sent over our connection-sharing protocol, that's 20 gigabits/second that will need to be both sent and processed for control-plane traffic alone.
A good question is whether we can make our cluster shared-stateless to avoid these operational challenges and still get the benefits of HA.
A brief digression on selecting a backend and connection state
Initially we need to choose one of N possible backends to service a new connection and then make sure that all traffic in that connection also gets sent to that same backend. Ideally we are also choosing backends in a balanced manner such that they all handle roughly the same number of connections.
We could choose a backend at random without too much fuss, but this introduces some complexity because we then need to remember – for additional packets in that connection – what backend was initially chosen. Basically we just need a table to store all of our connections with their chosen backend in. But as discussed above, this teeny bit of complexity begins to percolate through the rest of our system. Not only will we need to remember locally which backend was selected, but we'll also have to tell all the other load balancers which backend we chose, because if packets for that connection arrive there, then that load balancer is also going to need to choose the same one.
To avoid this complexity, we look for a way to deterministically route packets in a connection so that we don't have to do this sharing and all of our load balancers can independently determine where a packet should go without talking to each other. For example, we can assign a backend to a "bucket" and do a hash of something that is common to every packet in a connection – like the tuple of (source IP, source port, IP protocol number, destination IP, destination port) aka the 5-tuple – and map the range of hash outputs into discrete buckets. And here it seems we have escaped the need to keep track of – and thus share – connections if all endpoints are using the same hashing algorithm with the same set of backends. However with naïve hashing this strategy falls apart when backends are added or removed. If we add or remove buckets, the designated bucket for any given connection is very likely to change.
A solution is to use rendezvous hashing or consistent hashing, both of which are algorithms that minimize the reshuffling of hashed objects when the number of buckets changes.
Which leads us to, drumroll please...
HA without shared state
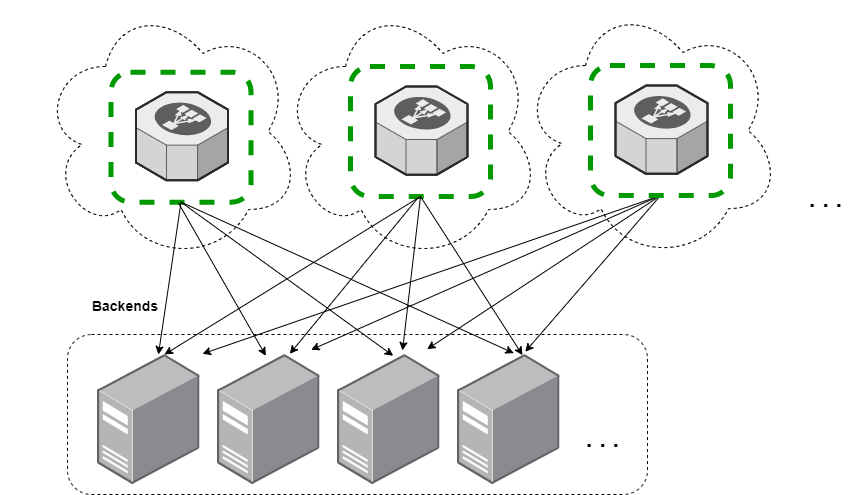
In 2016, Google published a paper detailing the architecture of their internal load-balancer called Maglev. In it they describe a system much like the one shown above, based on load-balancers that don't share state. Github has published the source of their similar system, glb-director. And there are others!
By utilizing variations on rendezvous hashing, these systems avoid the complexity of keeping global state while still allowing for a scale-out model.
One issue I've personally found investigating these solutions is that the source is unavailable (Maglev) or they are implemented using tools like dpdk which utilize Linux features that may require specific hardware (glb-director). But it turns out you can build a system like this just using well-understood Linux components like LVS and netfilter(iptables/nftables) that are already implemented in-kernel. And very fortuitously, Maglev hashing was added to LVS in ~2018!
Talk is cheap though, so I made a docker-based lab for investigating these properties. There's still a lot to be done here, I'd like to set up a test harness and do some additional tuning for faster convergence, but the basic setup works! Many thanks to Vincent Bernat for his excellent blog post detailing this architecture.
The next step for me is to make a test harness for this system to prove resiliency and then write everything up, stay tuned!