People will often ask me at parties, "how can you possible make stateful connections work with anycast addressing?"
I'm so glad you asked! If the issue here isn't immediately apparent to you, no worries, we'll dig in.
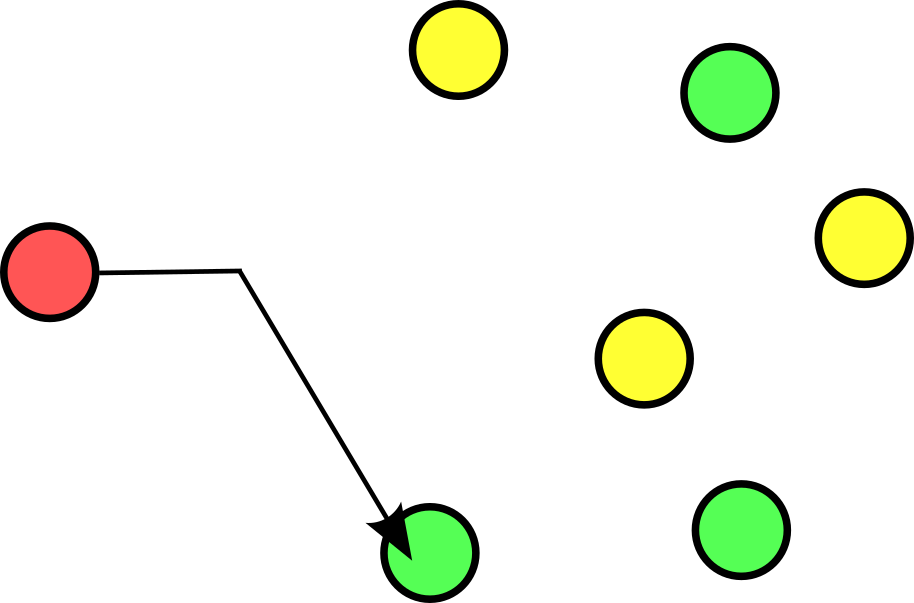
The above diagram is a basic representation of anycast addressing, where the node in red want to talk to a single address which can be routed to any of the green nodes. A really common use case for this is DNS; most folks are aware that the 8.8.8.8 or 8.8.4.4 Google DNS servers are not a single endpoint, but in fact many.
And here's proof:
Talking to 8.8.8.8 from my laptop in Hong Kong takes 2.33ms
~ ping 8.8.8.8
64 bytes from 8.8.8.8: icmp_seq=4 ttl=116 time=4.660 ms
and takes just 1ms from a VM I have in New York.
root@ubuntu-vpn-nyc:~# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=1.95 ms
This means the furthest the distance from my VM to the server replying to me can be is 300km, while the furthest it can be from me in Hong Kong is ~600km. I'd challenge you to find me the datacenter that fulfills both of these requirements!
Okay, so 8.8.8.8 is at least two separate servers, but admittedly this is not that interesting. Because DNS is just a single UDP request and reply, it makes total sense that our request can be served by any endpoint and then return to our public-facing IP.
If we are speaking TCP though, things are not quite so simple. Imagine a TCP handshake that went like this:
me to 8.8.8.8, landing at endpoint 1: SYN! I'd like to make a TCP connection!
server at endpoint 1 to me: SYNACK!
me to 8.8.8.8, landing at endpoint 2: ACK
server at endpoint 2: ????
How awkward, right? Unfortunately, there is no magic in the internet that is guaranteeing our packets always wind up at the same endpoint if there are multiple endpoints for a single address. And the Internet Protocol never promised us anything like this, all it cares about are addresses. If we decide to say we have one address available at multiple endpoints, then we are going to be responsible for handling them arriving at any of them for a given connection.
In reality, for short-lived TCP connections, it is likely to be the case that all packets in your connection take the same path simply due to the fact that packets are generally routed on the shortest path to their destination. And even though routes change all the time on the internet, they are unlikely to change on the order of seconds.
Why do we want this?
It's worth asking what benefit we get from an IP being able to route to multiple endpoints. In general, I think we understand that there can only ever be a single backend handling a connection. If a piano, cartoon-style, falls through the sky onto the rack holding the server that's processing a request there's very little we can do. But let's look at a typical setup for serving web requests.
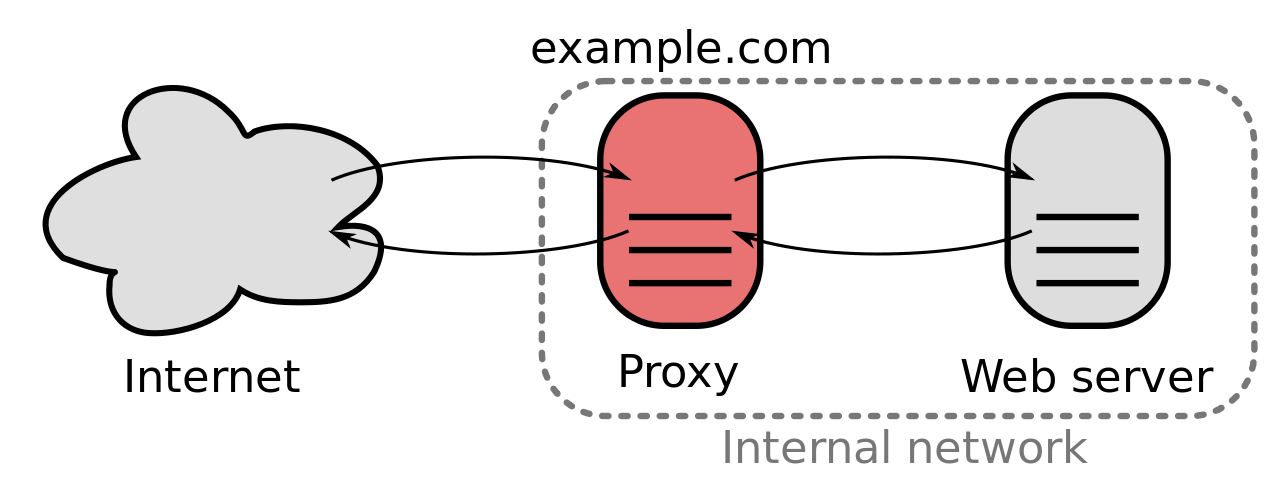
{kind=link}
Generally, the server handling the request is not exposed directly to the internet and a reverse proxy layer sits in front, providing load-balancing, caching, TLS termination, etc. This proxy layer is not just sitting in front of a single service, but several. It's generally specialized: it likely lives in a DMZ network zone and may have fancy hardware specifically for performing load-balancing. The redundancy we are looking to gain is in this proxy layer.
The number of proxy servers is <<< the number of total application instances, meaning in a naïve implementation losing a single proxy server results in large disruption to connections across many different applications. It also means that losing a proxy server is more likely than losing any given application server. If we assign the IP(s) we're designating to an application to just a single proxy server (because remember, we don't have anycast), we also have to handle failing over that IP to a new instance. If we don't, in addition to losing existing connections, we are also blocking new connections from being able to be made.
So let's say we've got something like the following requirements:
- Losing an endpoint has minimal, if any, impact to existing connections
- Automatic IP failover, or IP failover not required
- Losing a backend only impacts connections to that backend (the reason for this one will become more obvious when we talk about possible solutions)
Stay tuned for part 2 where we talk about solutions to these problems!